En Clarity, una de las tareas que estoy haciendo estos días es mejorar el rendimiento en el cálculo y persistencia de una colección de cálculos muy grande. Por usabilidad, una de las restricciones que nos hemos impuesto es que se tiene que hacer en menos de 5 segundos.
La ocurrencia
Entre otras cosas, para minimizar ese tiempo, hemos tenido la ocurrencia de agregar la información agrupándola por columnas, para persistirla así de forma física en Postgres.
Luego mediante el uso de vistas y de unas funciones PL/pgSQL podemos desagregar la información de forma lógica reconstruyendo las columnas originales:
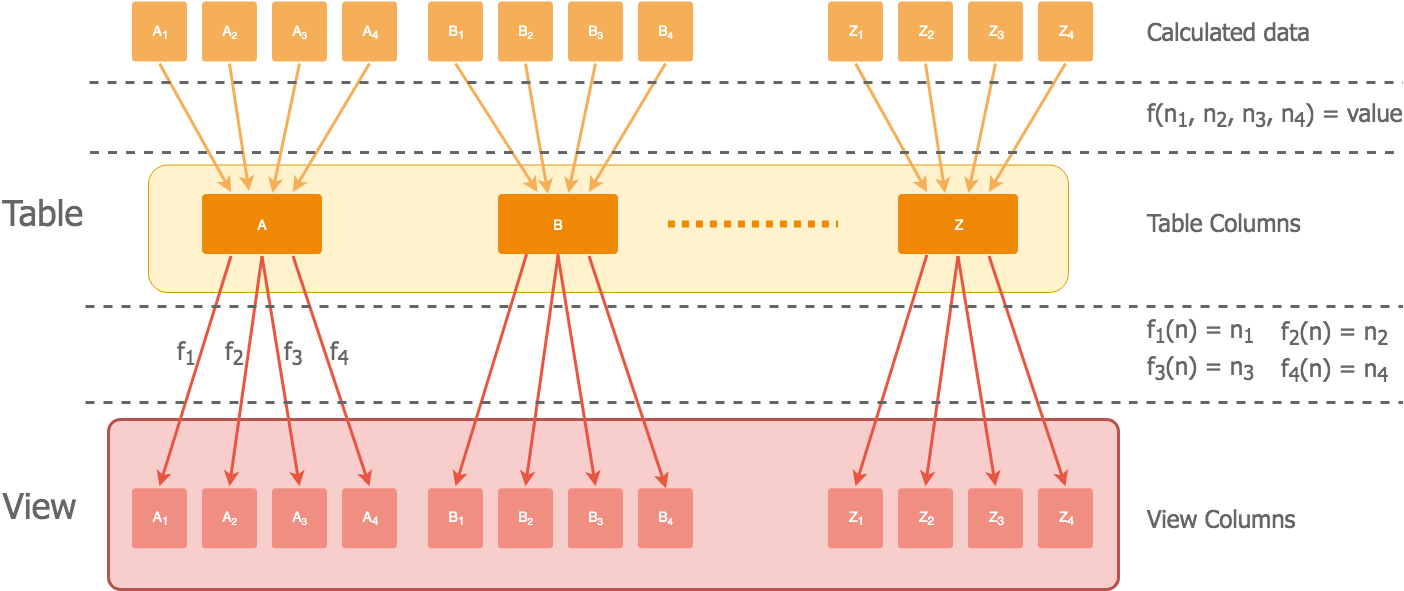
La función de agregación y las de desagregación son sencillas, no añaden mucho overhead, y no se pierde información en el proceso.
Como aún así el número de columnas es muy alto, hemos divido toda la información en 6 tablas, y luego según se necesite acceder a una información u otra, se hace una serie de joins contra la tabla principal.
Para simplificar la escritura de las queries, éstas se hacen contra las vistas en vez de contra las tablas con la información agregada. Montar una query teniendo que aplicar constantemente las funciones de desagregación no es problema, pero dificulta mucho la legibilidad y mantenibilidad el código.
Sobre el papel, y con todo lo que sabemos de bases de datos, es una solución un poco rebuscada pero que debería ir bien: todo el mundo usa intensivamente vistas y funciones PL/pgSQL, será coser y cantar.
El problema
¿Qué podría ir mal? ¿Qué problema tiene ésta estrategia? ¡Las consultas a la base de datos tardan 100 veces más que antes! Parece que no sabíamos tanto de base de datos y Postgres ….
Cuando estas trabajando con bases de datos, a la pregunta de “Me va lento, ¿qué puedo hacer?”, el 99% de los casos la respuesta está en los índices. Lo revisamos y parecían estar bien.
El ejemplo
Para entenderlo mejor pondré un ejemplo simplificado que reproduce el problema:
- Tabla x: 40 valores por fila, agrupados en 10 columnas
- Tabla y: 200 valores por fila, agrupados en 50 columnas
- Tabla z: 600 valores por fila, agrupados en 150 columnas
- Tabla w: 600 valores por fila, agrupados en 150 columnas
Las tablas tienen este aspecto:
CREATE TABLE table_x (id serial NOT NULL, org_id varchar NULL,
x_0 int4 NOT NULL, x_1 int4 NOT NULL, x_2 int4 NOT NULL, x_3 int4 NOT NULL,
x_4 int4 NOT NULL, x_5 int4 NOT NULL, x_6 int4 NOT NULL, x_7 int4 NOT NULL,
x_8 int4 NOT NULL, x_9 int4 NOT NULL
CONSTRAINT table_x_pkey PRIMARY KEY (id));
Las vistas se crearían aplicando la función de desagregación:
CREATE VIEW table_x_view AS
SELECT org_id,
calcA(x_0, 1) x_0_alpha, calcA(x_0, 2) x_0_beta, calcA(x_0, 3) x_0_gamma, calcA(x_0, 4) x_0_delta,
calcA(x_1, 1) x_1_alpha, calcA(x_1, 2) x_1_beta, calcA(x_1, 3) x_1_gamma, calcA(x_1, 4) x_1_delta,
calcA(x_2, 1) x_2_alpha, calcA(x_2, 2) x_2_beta, calcA(x_2, 3) x_2_gamma, calcA(x_2, 4) x_2_delta,
calcA(x_3, 1) x_3_alpha, calcA(x_3, 2) x_3_beta, calcA(x_3, 3) x_3_gamma, calcA(x_3, 4) x_3_delta,
....
FROM table_x;
Y una de las funciones de desagregación podría tener esta pinta:
CREATE FUNCTION calcA(value int4, mult int4)
RETURNS int4 AS $$
BEGIN
RETURN value * mult;
END;
$$ LANGUAGE plpgsql;
(la función es un ejemplo que representa que tiene coste O(1), no es un caso real)
El DDL completo lo podéis encontrar aquí.
Una query sencilla que pregunta solamente por 5 valores de las tablas/vistas sería esta:
select table_x_view.org_id, table_x_view.x_0_alpha, table_y_view.y_10_beta,
table_z_view.z_100_gamma, table_w_view.w_120_delta
from table_x_view
join table_y_view on (table_x_view.org_id = table_y_view.org_id)
join table_z_view on (table_x_view.org_id = table_z_view.org_id)
join table_w_view on (table_x_view.org_id = table_w_view.org_id)
Explain query plan
Si ejecutamos un explain completo (EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)) sobre la query y la llevamos a una herramienta de visualización, encontramos que donde se va la mayor parte del tiempo es en hacer un escaneo secuencial de las tablas, sobre todo las que más columnas tienen:
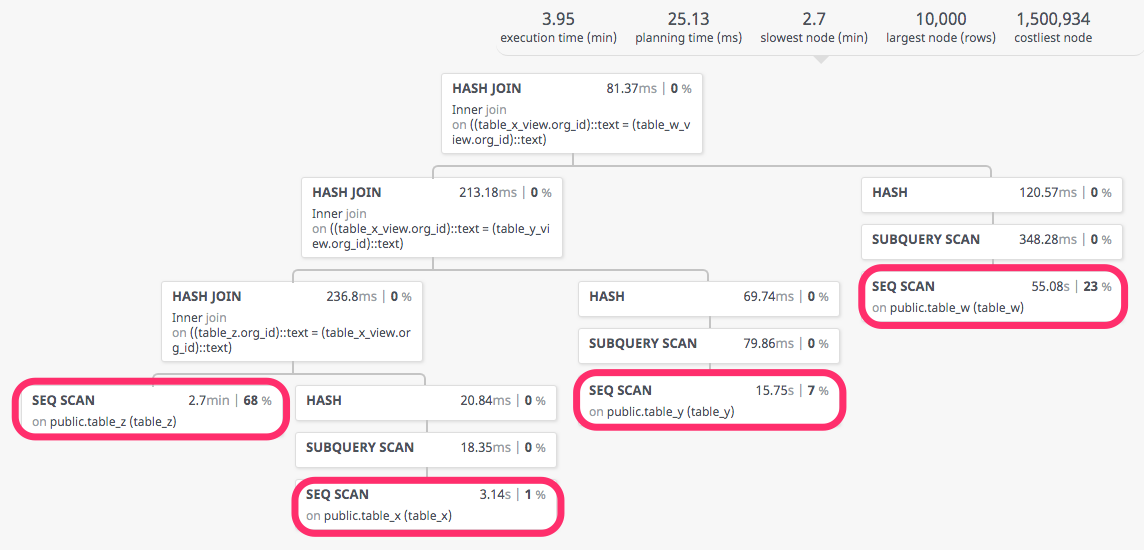
Para que podáis jugar con la visualización podéis encontrar el json generado en el explain aquí
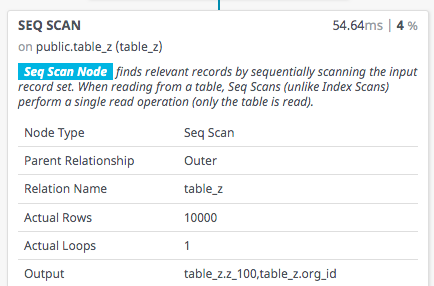
Al expandir el nodo que más tiempo emplea, vemos que en el Output aparece aplicada la función de desagregación de todas las columnas, aunque en la query sólo estemos preguntando por uno de los valores:
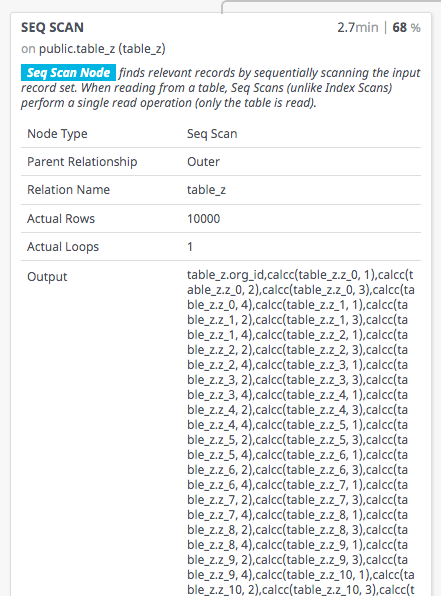
Sí sólo es necesario un valor de vista, ¿por qué el planificador/optimizador de Postgres calcula todas las columnas de las vistas? Está claro que el valor no participa en ningún momento en el join ni en el where, simplemente accedemos a él en el select.
La causa
El problema radica en que Postgres no sabe qué hace la función de desagregación y no puede hacer las optimizaciones necesarias.
Siempre se ha dicho SQL es un lenguaje declarativo de alto nivel y no procedimental, donde se especifica lo que se quiere pero no cómo conseguirlo. Pero esto se rompe en cuanto metemos en la ecuación funciones, que no tienen porqué comportarse igual que el SQL declarativo: pueden tener efectos colaterales.
Una función PL/pgSQL puede hacer cualquier cosa en su implementación, como por ejemplo ejecutar inserciones y actualizaciones. Estas operaciones modifican el estado de la base de datos y por tanto el orden en el que se ejecutan es importante.
La base de datos al encontrarse las vistas no tiene el conocimiento suficiente sobre los efectos de lado que provoca. No sabe qué comportamiento tienen los elementos que la forman, por lo que se pone en un caso pesimista y considera que es necesario “instanciar” los elementos de la vista antes de hacer uso de la misma. Probablemente si hiciera algún tipo de análisis estático del código podría inferirlo, pero por ahora no tiene esa capacidad.
Si tenemos la certeza de que nuestra función no modifica el estado y de que devuelve siempre el mismo resultado dadas las mismas entradas (idempotente), podemos ayudar a la base de datos indicando que la función es IMMUTABLE.
Por defecto, si no especificas lo contrario, todas las funciones son declaradas como VOLATILE y considerará que tu implementación tiene efectos de lado.
Si modificamos la declaración de función añadiéndole el modificador IMMUTABLE
CREATE FUNCTION calcA(value int4, mult int4)
RETURNS int4 AS $$
BEGIN
RETURN value * mult;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
conseguiremos que el tiempo de ejecución se reduzca a algo lógico y el plan de ejecución cambie por completo:
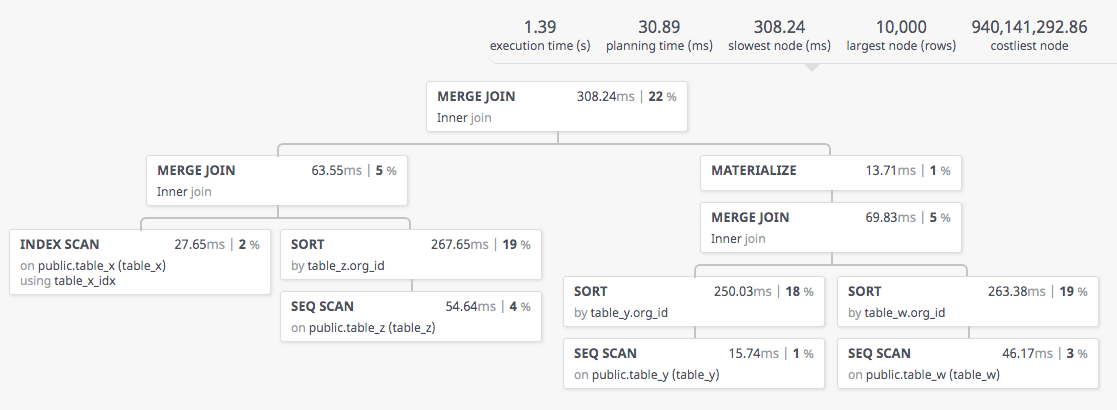
El nuevo explain completo en json lo podéis encontrar aquí
Si expandimos la información del nodo podemos ver que la única información que extrae de la tabla es la columna sobre la que ejecutará la función de desagregación, pero sin aplicarla:
Si recorremos todo el árbol de evaluación, vemos que no ejecuta el cálculo hasta que llega al nodo raíz:

Conclusión
Crear el nuevo modelo de tablas, cambiar la forma de persistir los datos y validar que era todo correcto funcionalmente me llevó un valioso tiempo.
Cuando fui a validar con datos reales que todo seguía funcionando bien y me encontré esos tiempos de ejecución la decepción fue mayúscula… no me podía creer que las bases de datos en general y Postgres en particular no pudieran lidiar con un pequeño cambio y diera unos resultados desastrosos.
Llegar hasta esta solución me costó bastante, porque en ninguna parte encontré (o no he sabido encontrar) nada que relacionara una penalización de rendimiento en el uso de vistas en combinación con funciones. ¿Es algo de primero de base de datos? ¿tú lo sabías antes de leer este post?
Por fortuna no perdí la fe en las capacidades de Postgres, y releyendo la documentación sobre funciones y procedimientos di con el modificador y até cabos.