Parquet es un formato ampliamente utilizado en el mundo del Data Engineering y posee un potencial considerable para aplicaciones de Backend tradicionales. Este artículo es una introducción sobre el formato y de las cosas raras que he encontrado cuando he querido usarlo, para que no tengas que pasar por lo mismo.
Introducción
Apache Parquet, publicado por Twitter y Cloudera en 2013, es un formato de archivo columnar eficiente y de propósito general para el ecosistema de Apache Hadoop. Inspirado en el paper “Dremel: Interactive Analysis of Web-Scale Datasets” de Google, Parquet está optimizado para soportar estructuras de datos complejas y anidadas.
Aunque emergió casi simultáneamente con ORC, de Hortonworks y Facebook, parece que el formato que ha acabado triunfando ha sido Parquet.
A diferencia de los formatos orientados a filas, Parquet organiza los datos por columnas, facilitando una persistencia de datos más eficiente mediante técnicas avanzadas de codificación y compresión.
Tabla lógica
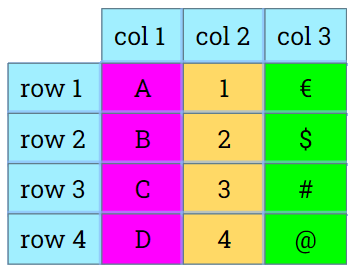
Almacenamiento orientado a filas:

Almacenamiento orientado a columnas:

En tiempo de lectura, si no necesitas acceder a todas las columnas, al estar toda su información junta te puedes ahorrar leer y procesar muchos bloques de datos.
Regla número 1 del "data engineering": el dato más rápido es el que no se lee.
— javi santana (@javisantana) January 22, 2021
Miles de horas invertidas en leer y filtrar datos que nunca deberían haberse leídos
El formato de datos columnar se utiliza a menudo en sistemas de bases de datos analíticos como (Cassandra, BigQuery, ClickHouse, QuestDB) y en sistemas de procesamiento de grandes conjuntos de datos, como Apache Arrow u ORC
Formato
Los datos en Parquet se almacenan en binario, lo que los hace ilegibles al ser impresos en consola, a diferencia de otros formatos basados en texto como JSON, XML o CSV.
Dado que su objetivo radica en almacenar una gran cantidad de datos, es asequible guardar además la información del esquema en los propios archivos y otros metadatos estadísticos. Esto permite trabajar con ficheros de los que no sabes a priori su esquema. Dado un fichero Parquet, contiene toda la información necesaria para descubrir su esquema y poder leerlo.
Parquet soporta tipos de datos básicos, con la posibilidad de extenderlos mediante tipos lógicos, dándoles su propia semántica:
- BOOLEAN: booleano de 1 bit (boolean en Java)
- INT32: entero con signo de 32 bits (int en Java)
- INT64: entero con signo de 64 bits (long en Java)
- INT96: entero con signo de 96 bits (sin equivalencia directa en Java)
- FLOAT: valor en coma flotante IEEE de 32 bits (float en Java)
- DOUBLE: valor en coma flotante IEEE de 64 bits (double en Java)
- BYTE_ARRAY: array de bytes de tamaño indeterminado
- FIXED_LEN_BYTE_ARRAY: array de bytes de tamaño fijo
Los String, Enum, UUID, y los distintos tipos de fechas se pueden construir a partir de esos tipos básicos.
El formato soporta persistir estructuras de datos complejas, listas y mapas de forma anidada, lo que nos abre la puerta a guardar cualquier tipo de datos que se pueda estructurar como un Documento.
Históricamente las colecciones se pueden representar internamente de múltiples maneras, dependiendo de cómo quieras gestionar que una colección pueda ser null o vacía. A su vez, también como detalle de implementación, cómo nombrar cada elemento de la colección puede variar entre implementaciones del formato. Estas variaciones ha llevado a que distintas utilidades de diferentes lenguajes generen ficheros con diferencias que los hagan incompatibles.
Oficialmente ya se ha definido la forma correcta de representar las colecciones, pero muchas herramientas manteniendo la compatibilidad hacia atrás, siguen generando ficheros con las representaciones legacy, y es necesario configurar explícitamente que escriban en la forma “correcta”. En Pandas con PyArrow tendrás que activar use_compliant_nested_type, mientras que Avro Parquet en Java tendrás que desactivar el flag WRITE_OLD_LIST_STRUCTURE_DEFAULT.
Aunque Parquet tiene un IDL para definir el formato de los datos contenidos en un fichero (su schema), no proporciona directamente una herramienta estándar para, dado un IDL, generar código Java que permita serializar y deserializar datos en Parquet.
Parquet embebe dentro de su codificación el comprimir la información. De forma directa hace compresión Run-length encoding (RLE) o Bit Packing, y de forma opcional permite configurar si queremos comprimir bloques de datos usando compresores como Snappy, GZip o LZ4, y si queremos usar Diccionarios para normalizar los valores repetidos.
Por defecto se suele usar compresión Snappy, ya que tiene un buen ratio de compresión/tiempo CPU.
A la hora de serializar o deserializar muchos datos nos permite escribir o leer los registros uno a uno, sin necesidad de tenerlos todos en memoria como en el caso de Protocol Buffers o FlatBuffers. Puedes serializar un stream de registros o iterar un fichero leyendo registros uno a uno.
Documentación
A pesar de la relevancia que tiene el formato en el mundo del Data Engineering, la documentación sobre su uso básico es bastante escasa, sobre todo en Java.
¿Cómo te sentirías si para aprender sobre cómo leer o escribir ficheros JSON tuvieras que pasar por Pandas o Spark y no fuera sencillo hacerlo directamente? Esa es la sensación que tienes cuando empiezas a estudiar sobre Parquet.
Las herramientas de alto nivel que suele usar un Data Engineer (Pandas, Spark, …) ya le proporcionan los métodos para exportar e importar directamente su información a Parquet (u otros formatos), por lo que le abstrae de los detalles. Pero es difícil encontrar documentación y ejemplos sobre su uso fuera de esas utilidades, o está dispersa a lo largo de diferentes artículos que ha ido escribiendo la gente.
¿Qué dirías si para leer o escribir ficheros JSON tuvieras que pasar por otras herramientas/formatos como Avro o Protocol Buffers y no hubiera una librería que lo soporte directamente? Eso es lo que pasa con Parquet.
El hecho de que no exista una librería que dé un soporte sencillo para trabajar con ficheros Parquet, y tengas que recurrir a terceras librerías que serializan otros formatos no ayuda a aterrizar en el mundo Parquet.
Librerias
La librería de Parquet en Java no ofrece una manera directa de leer o escribir archivos Parquet. Al igual que la librería Jackson maneja archivos JSON o la librería Protocol Buffers trabaja con su propio formato, Parquet no incluye una función para leer o escribir Objetos Java (POJOs) o estructuras de datos propias de Parquet.
Para usar Parquet en Java, tienes dos opciones:
- Utilizar el API de bajo nivel proporcionado por la librería Parquet directamente (sería equivalente a procesar los tokens de un parser JSON o XML).
- Aprovechar las capacidades de otras librerías de serialización, como Avro o Protocol Buffers.
Entre las librerías que forman el proyecto Apache Parquet en Java existen unas que, usando las clases e interfaces de Protocol Buffers o Avro, leen y escriben archivos Parquet. Estas librerías utilizan el API de bajo nivel de parquet-mr para convertir objetos de tipo Avro o Protocol Buffers en archivos Parquet y viceversa.
En resumen, al trabajar con Parquet en Java, estarás utilizando tres tipos de clases correspondientes a tres APIs distintas:
- El API de la librería de serialización que elijas, que proporciona la forma de definir los Objetos serializados e interactuar con ellos.
- El API de la librería wrapper de la librería de serialización que hayas elegido. Los lectores (Readers) y escritores (Writers) de estos Objetos.
- El API de la propia librería de bajo nivel de
parquet-mrque define interfaces y configuraciones comunes, e implementa la serialización en sí.
La librerías más fácil, flexible y que más frecuentemente encontrarás en ejemplos de Internet es Avro, aunque también puedes usar Protocol Buffers.
Que se usen utilidades de estos formatos no significa que se serialice dos veces la información, pasando primero por un formato intermedio, sino que se reutilizan esas clases creadas por Avro o Protocol Buffers, y que contendrán los datos a persistir. Cada implementación wrapper usa el API de Parquet MR.
La abstracción sobre ficheros
La librería de Parquet no sabe dónde está localizada la información: si está en tu sistema de ficheros local, en un cluster de Hadoop, o en S3.
Para abstraernos de donde están los ficheros define las interfaces org.apache.parquet.io.OutputFile y org.apache.parquet.io.InputFile con métodos para obtener unos tipos especiales de output e input stream con los que manejar los datos.
De esas interfaces provee una implementación encargada de implementar el acceso a ficheros en Hadoop, SFTP o ficheros locales:
Esas implementaciones a su vez requieren que referencies los ficheros mediante la clase org.apache.hadoop.fs.Path, que no tiene nada que ver con la clase Path de Java, junto con un org.apache.hadoop.conf.Configuration
Para referenciar un fichero necesitaremos escribir un código como este:
Path path = new Path("/tmp/my_file.parquet");
OutputFile outputFile = HadoopOutputFile.fromPath(path, new Configuration());
InputFile inputFile = HadoopInputFile.fromPath(path, new Configuration());
Pero afortunadamente eso no durará mucho, porque recientemente se ha mergeado a master una segunda implementación que permite trabajar sólo con ficheros locales y se está desacoplando de la clase de configuración de Hadoop. Todavía no se ha hecho ninguna release que lo contenga, y se espera que estén para la versión 1.14.0.
Dependencias
Uno de los mayores inconvenientes que tiene usar Parquet en Java es el gran número de dependencias transitivas que tienen sus librerías.
Parquet se concibió para ser usado junto con Hadoop. El projecto en GitHub de la implementación de Java se llama parquet-mr, y mr viene de Map Reduce. Como puedes ver el package de las clases de ficheros referencia a hadoop.
Con el tiempo ha ido evolucionando e independizándose, pero no ha conseguido desacoplarse del todo de él y todavía tiene muchas dependencias transitivas de las librerías que usa Hadoop (desde un servidor Jetty, a un cliente de Kerberos o Yarn).
Si tu proyecto va a hacer uso de Hadoop, todas esas dependencias serán necesarias, pero si lo que pretendes es usar ficheros normales fuera de Hadoop, hace que tu aplicación sea más pesada. Yo os sugiero excluir esas dependencias transitivas en vuestro pom.xml o build.gradle.
Aparte de incluir mucho código innecesario, puede suponer un problema al resolver conflictos de versiones de dependencias transitivas que tú también estés usando.
Si no excluyes ninguna dependencia, puedes encontrarte con más de 130 JARs y 75 MB en tu artefacto desplegable. Excluyendo cuidadosamente las dependencias que no uso, he llegado a tener sólo 30 JARs que consumen entre 23 y 29MB.
Como he comentado antes, se está trabajando en ello, pero todavía no está todo listo.
Conclusión
El formato Parquet se erige como una herramienta crucial en el ecosistema de Data Engineering, proporcionando una solución eficiente para el almacenamiento y procesamiento de grandes volúmenes de datos.
Aunque su adopción ha sido sólida en entornos de Big Data, su potencial trasciende estos ámbito y puede ser aprovechado también en el mundo del Backend tradicional.
Su diseño orientado a columnas, junto con sus capacidades avanzadas de compresión y estructuración de datos complejos, lo convierten en una opción robusta para aquellos que buscan mejorar el rendimiento y la eficiencia en la manipulación de datos dentro de entornos de Backend tradicionales.
Pese a sus ventajas indiscutibles, la adopción de Parquet como formato de intercambio de datos en el desarrollo de aplicaciones Java se enfrenta a obstáculos, principalmente debido a la complejidad de su API de bajo nivel y la falta de una interfaz de alto nivel que simplifique su uso. La necesidad de recurrir a bibliotecas de terceros añade una capa adicional de complejidad y dependencias, y la escasez de documentación accesible y ejemplos concretos constituyen una barrera significativa para muchos desarrolladores.
Este post ha sido una introducción al formato, sus ventajas y los WTF que me he encontrado, no os desaniméis. Una vez asimilada esta información, los próximos post tratarán sobre cómo trabajar con Parquet usando distintas librerías: